
Introduction
I’m a Gen-X music collector who came of age in the 1980s and 1990s, when CDs were the definitive format for building a serious music library. Over the years, I accumulated thousands of discs, Including: domestic releases, imports, singles, remixes, and obscure pressings, carefully curated long before streaming platforms made music feel disposable.
Even back then, before streaming became mainstream, I had already started thinking about the problem CDX now aims to solve: what if my physical CD collection could be treated like a searchable database? I wanted to understand what I owned, not just by album or artist, but by credits, features, producers, alternate versions, and regional releases. At the time, the tools simply didn’t exist, and building something myself felt far more complex than the payoff justified.
Fast forward to today, and the technology landscape has changed dramatically. What hasn’t changed is the underlying problem, how to intake large volumes of physical “things,” enrich them with external data, handle ambiguity, and make the results discoverable. That problem is not unique to music collections; it’s one of the most common workflows in enterprise systems.
CDX is designed to model that exact business process.
While CDs serve as the concrete input, CDX is intentionally built as a reference architecture for enterprise intake pipelines, the same patterns used to process inventory, orders, assets, or scanned records. Physical media simply provides a realistic, edge-case-rich way to explore those patterns end-to-end.
What Is CDX?
At a functional level, CDX models a familiar enterprise workflow:
Intake → Validation → Queueing → Processing → Enrichment → Storage → Discovery
Although the UI and terminology reference CDs, each stage directly corresponds to a common business system pattern.
Enterprise Process Mapping
| Enterprise Concept | CDX Implementation |
|---|---|
| Widget intake | Barcode scan / manual entry |
| Batch submission | Scan session upload |
| Validation | Intake API payload checks |
| Durable queue | AWS SQS |
| Async processing | Local enrichment worker |
| External systems | MusicBrainz / Discogs APIs |
| Normalization | Canonical album / track models |
| Master data store | Local PostgreSQL |
| Human review | Ambiguous match & rare-track queues |
| BI / discovery | Browse, search, insights UI |
CDs are an ideal stand-in for enterprise “widgets” because they:
- are physical items requiring intake
- have globally unique identifiers (UPC/EAN)
- require enrichment from external systems
- introduce ambiguity and exceptions
- naturally support batch processing
UX Vision
Before writing any code, I focused on how CDX should feel to use.
Scan & Intake (Utility-First)
- Mobile-friendly PWA interface
- Fast barcode scanning
- Batch intake for large collections
- Manual barcode entry as a fallback
- Minimal UI chrome, optimized for speed
Browse & Discover (Catalog-First)
- Album-centric browsing
- Track-level and credit-aware search
- Dedicated “rare tracks” views
- Clean, internal-tool aesthetic

Technologies, Platforms, and Languages
CDX is intentionally built using production-proven, enterprise-relevant technologies. The goal is not novelty, but to demonstrate sound architectural judgment, cost awareness, and operational realism.
Core Languages
- Python — Primary language across the platform (web app, workers, serverless)
- HTML / CSS — Server-rendered UI focused on clarity and accessibility
- Minimal JavaScript — Used only where required (camera access, barcode decoding, PWA support)
Web Framework & UI Layer
- Flask
Lightweight, flexible web framework well-suited for internal tools and clean architecture. - HTMX
Enables dynamic UI interactions (search, batching, queues) without a full SPA, keeping the system easy to reason about and maintain. - Progressive Web App (PWA)
The scan interface is implemented as a PWA, providing:- mobile-friendly behavior
- install ability
- offline-aware design (future phase)
Data & Persistence
- PostgreSQL (On-Prem)
Acts as the canonical data store for:- albums
- tracks
- artist credits
- scan events
- enrichment and review state
Messaging & Asynchronous Processing
- AWS Simple Queue Service (SQS)
Provides durable, decoupled messaging between intake and processing, enabling retry handling and back-pressure management.
Cloud Platform
- AWS API Gateway + AWS Lambda
Used as a thin, stateless intake layer to validate scan submissions and enqueue work. No persistent storage or long-running compute is placed in the cloud.
Networking & Security
- NetBird (Zero Trust VPN)
CDX is private by default. All access is restricted via NetBird, mirroring modern enterprise Zero Trust networking models with private DNS and encrypted tunnels.
Development Tooling
- UV — Python package and project manager for fast, reproducible environments
- GitHub — Repository hosting, documentation, and phased delivery tracking
Overall Design Architecture (On-Prem + AWS)
CDX follows a hybrid architecture that separates intake, processing, and discovery while aligning each component with the environment best suited for its role.
Architectural Principles
- Private by default
- Cloud only where it adds value
- Local-first processing and storage
- Asynchronous, queue-backed workflows
- Deployment-aligned system boundaries
High-Level Process Flow & Architecture Diagram
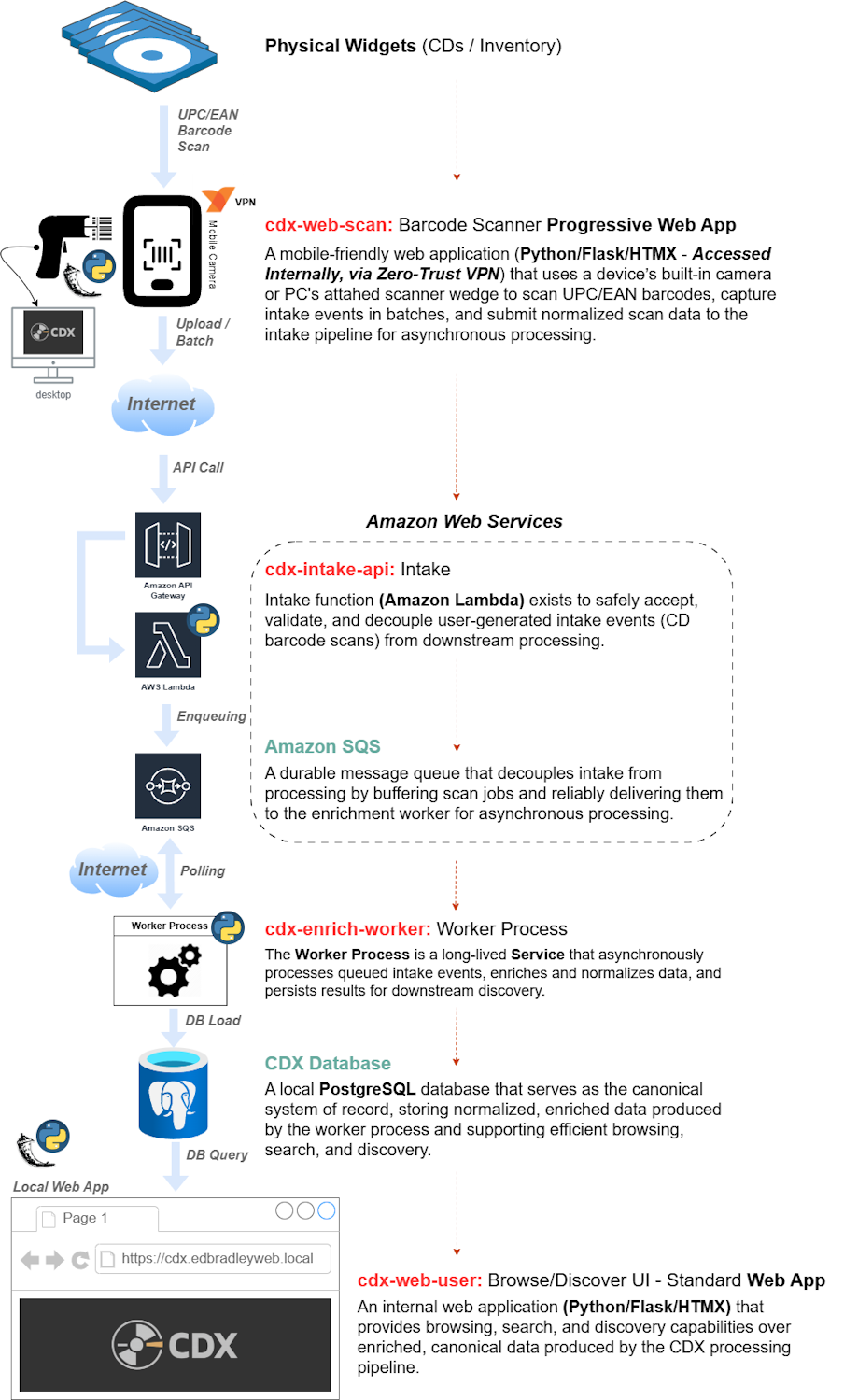
Why This Hybrid Model Works
This architecture mirrors real-world enterprise platforms:
- Cloud handles edge durability and availability
- On-prem handles processing, enrichment, and sensitive data
- Queues decouple workflows and improve resilience
- Local storage avoids recurring cloud database costs
CDX intentionally demonstrates how modern systems can combine cloud services with local infrastructure in a clean, maintainable way.
Repository Strategy (Minimal, Deployment-Aligned)
CDX is intentionally split into three repositories, each mapping directly to a deployment unit:
cdx-web-scan
- Flask + HTMX web application
- Scan UI
- PWA assets
- Internal access only
cdx-intake-api
- Thin AWS intake layer
- API Gateway + Lambda (Python)
- Publishes scan jobs to SQS
cdx-enrich-worker
- Local processing service (Python)
- Metadata enrichment and normalization
- Database schema and migrations
- Exception and rare-track detection
cdx-web-user
- Flask + HTMX web application
- Browse albums, tracks, and artists
- Credit-aware and natural-language search
- Rare-track and exception views
- Collection insights and metrics
- Read-only access to canonical data
This structure avoids premature abstraction while clearly modeling enterprise system boundaries.
Why These Technology Choices
CDX is intentionally boring, in the best possible way.
Every technology choice reflects patterns commonly found in real enterprise systems: thin intake layers, queue-backed processing, local enrichment services, and secure internal access. The focus is on architecture, sequencing, and decision-making, not novelty frameworks.
Roadmap
Phase 1 (This Post)
- Vision
- UX mockups
- Repository scaffolding
Phase 2
- Camera-based scanning
- Batch intake
- AWS intake pipeline live
Phase 3
- Metadata enrichment
- Search and discovery
- Rare track identification
Wrap up
While CDX is inspired by a personal CD collection, its true purpose is to model a realistic enterprise intake, enrichment, and discovery workflow, one that could just as easily apply to inventory systems, order pipelines, asset management, or operational tooling.