Introduction
In this post, I cover how I leveraged AWS SQS (Simple Queue Service) to ingest collected EAN/UPC barcode scans from the CDX Web Scan application to be be fed into a forthcoming discovery and enrichment service (cdx-enrich-worker).
The CDX Web Scan application (cdx-web-scan) forwards batches of barcode scans to an AWS Lambda function via Amazon API Gateway. As shown in the pipeline diagram excerpt below, the Python-based Lambda function parses the incoming scan payload from the API request and enqueues each individual scan into SQS for downstream processing:
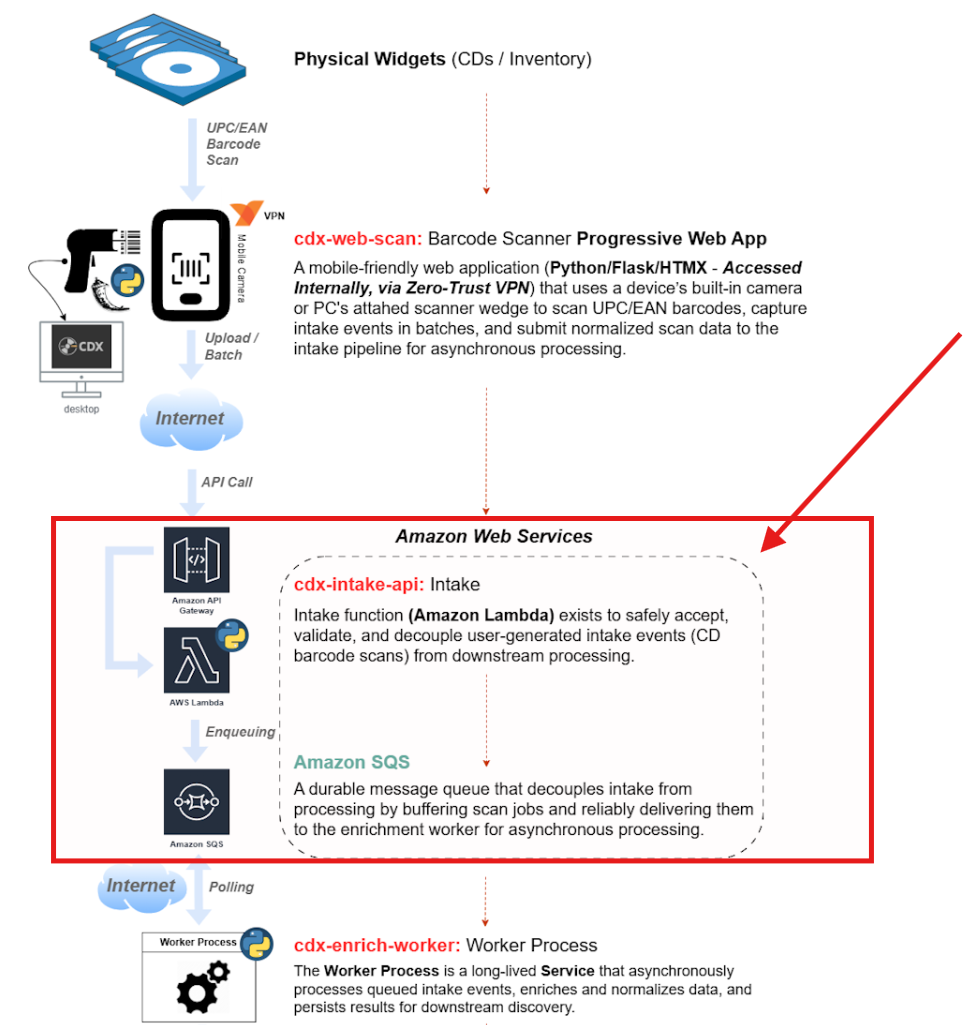
Given the size of my CD collection (roughly 2,500 CDs), this approach provides a low-to-near-zero-cost, cloud-native, serverless architecture that allows me to model a durable, enterprise-style intake and processing pipeline without the overhead of additional server infrastructure.
Setting up the Intake Queue using Amazon SQS
The first step in building the cloud portion of the CDX pipeline was establishing a durable intake queue to hold incoming batches of barcode scans. For this, I used Amazon SQS (Simple Queue Service), which provides a highly reliable, fully managed message queuing service well-suited for serverless, event-driven architectures.
Using the AWS Web Console, I created both a primary intake queue and a Dead-Letter Queue (DLQ).
An Amazon SQS dead-letter queue (DLQ) is a secondary queue that stores messages that cannot be successfully processed by a consumer after a defined number of retries. This pattern is critical for production-grade systems because it:
- Isolates problematic or malformed messages for later inspection
- Prevents failed messages from blocking or slowing down the main queue
- Improves overall system resilience and fault tolerance
Creating the Dead-Letter Queue (DLQ):
I created the DLQ first so it could later be associated with the primary intake queue.
In the AWS Web Console, I navigated to Amazon SQS and selected Create queue. I chose a Standard queue (rather than FIFO, since strict ordering was not required at this stage) and left the default settings in place. I named the queue:
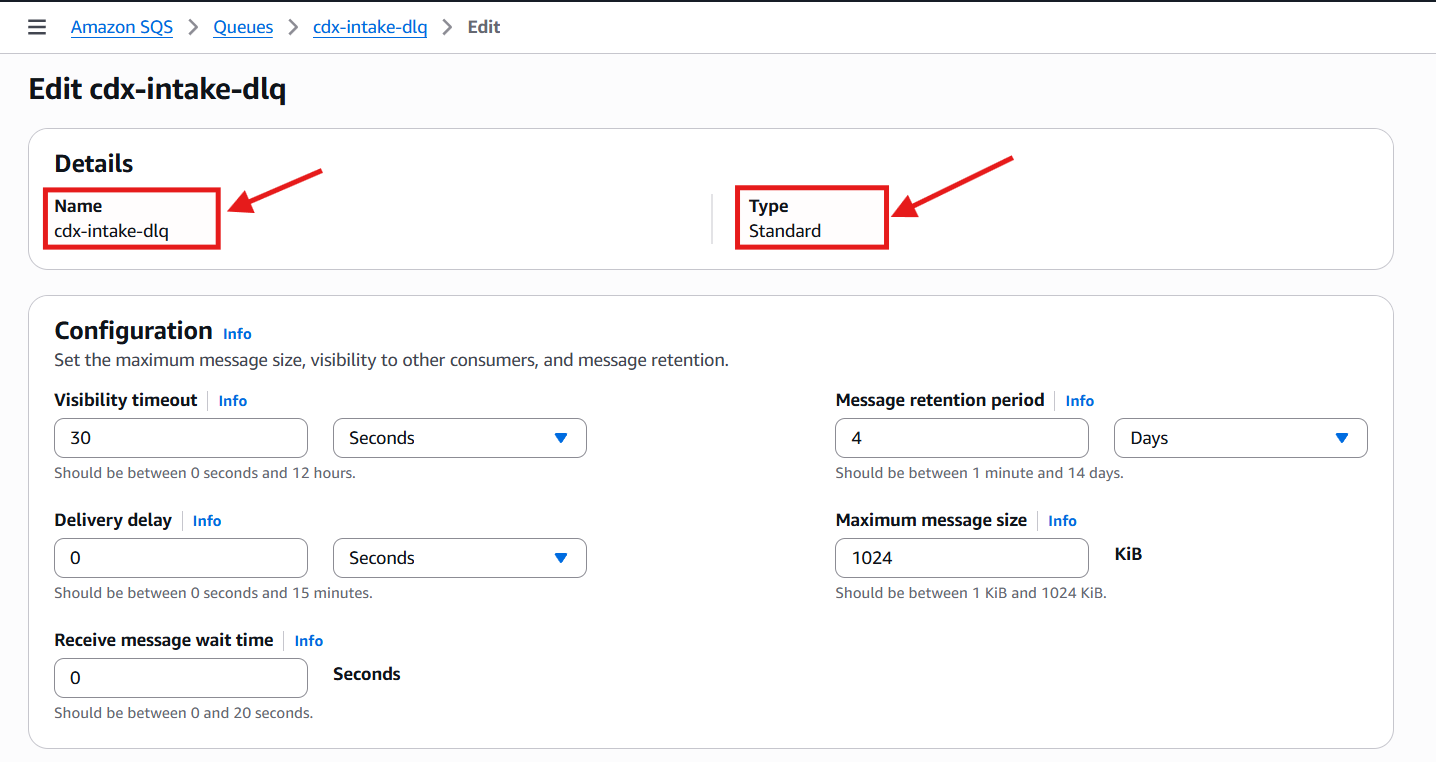
cdx-intake-dlq
This queue would serve as the holding area for any scan messages that fail downstream processing and require investigation or replay:
Creating the Main CDX Intake Queue:
With the DLQ in place, I created the primary intake queue, named:
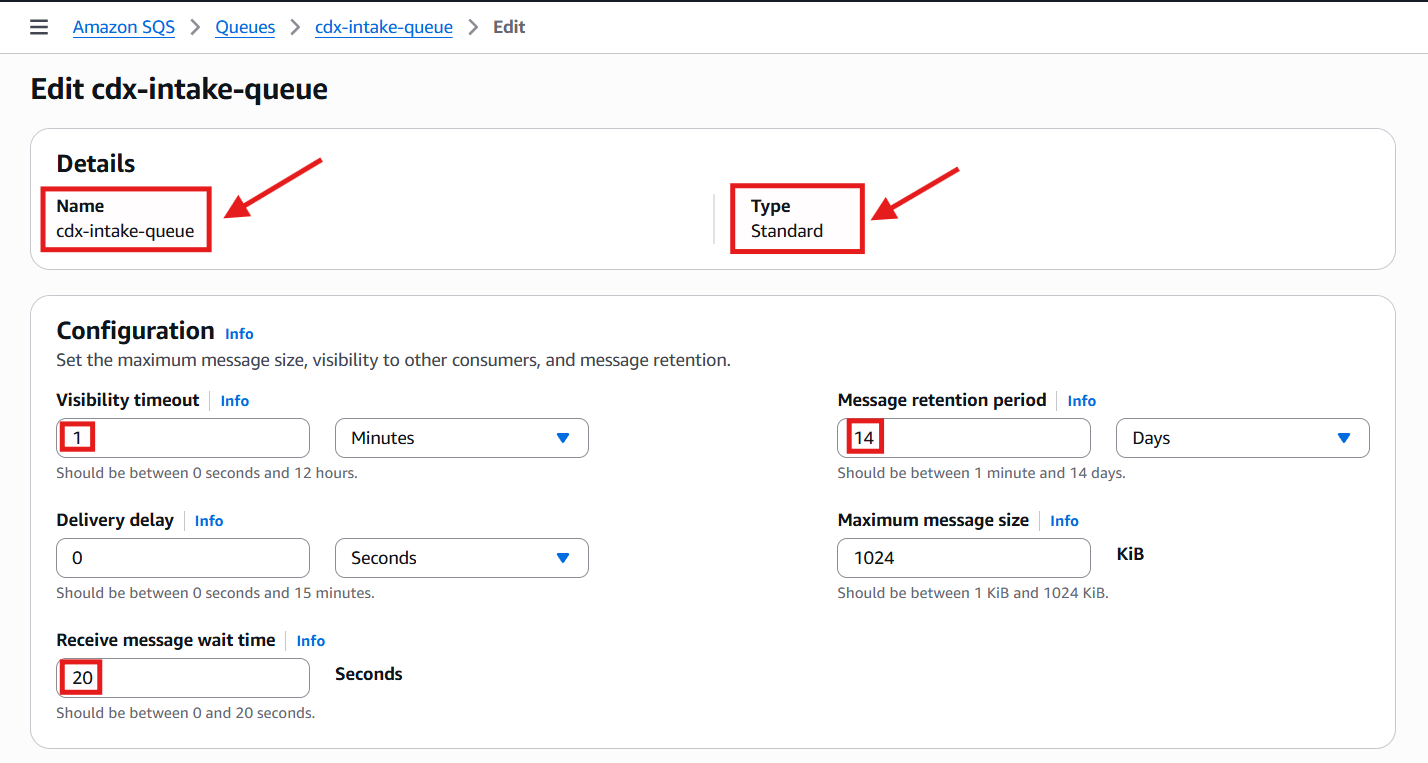
cdx-intake-queue
This is also a Standard SQS queue, but I adjusted some configuration settings to better support the CDX intake workflow:
- Visibility timeout: Increased to 1 minute (from the default 30 seconds)
- This allows sufficient time for downstream workers to process each message without it being prematurely re-queued.
- Receive message wait time: Increased to 20 seconds
- Enables long polling, which reduces empty responses and lowers overall API costs.
- Message retention period: Increased to 14 days
- Provides additional safety during extended outages or maintenance windows, ensuring no scans are lost.
Finally, I associated the main intake queue with the previously created Dead-Letter Queue, completing the fault-handling configuration:
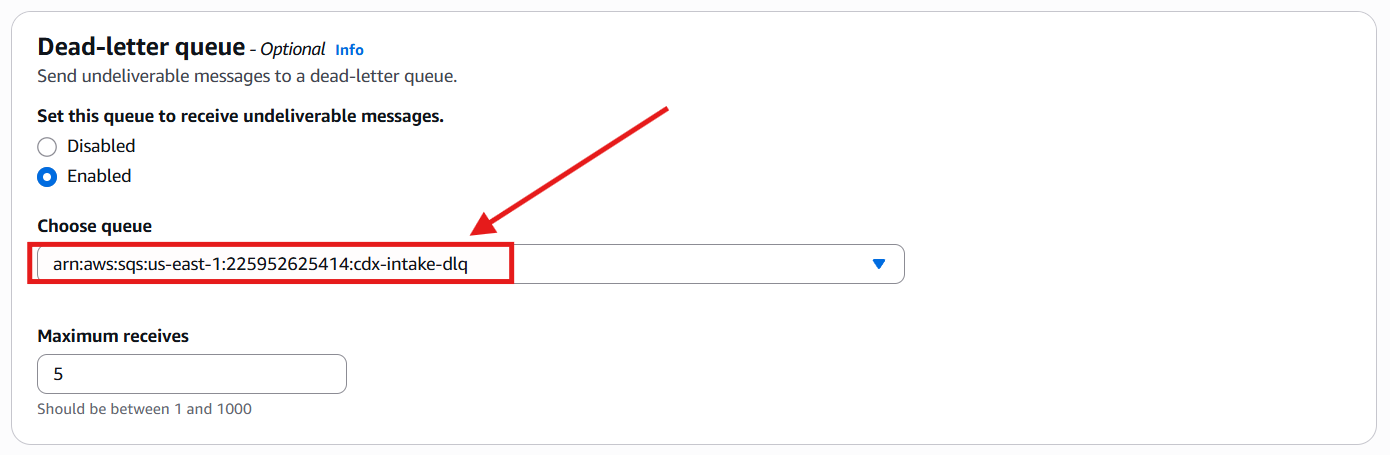
At this point, Amazon SQS was fully prepared to receive and persist individual barcode scan messages.
Creating an IAM Role for the Lambda Function:
With the intake queue ready, the next step was to create an IAM role that allows the Lambda function to send messages to SQS.
In IAM → Roles, I created a new role named:
cdx-intake-lambda-role
This role includes two policies:
- AWSLambdaBasicExecutionRole
- An AWS-managed policy that grants permissions for writing logs to Amazon CloudWatch Logs, which is essential for debugging and observability.
- cdx-intake-send-to-sqs (custom inline policy)
- Grants the Lambda function permission to send messages to the
cdx-intake-queue.
- Grants the Lambda function permission to send messages to the
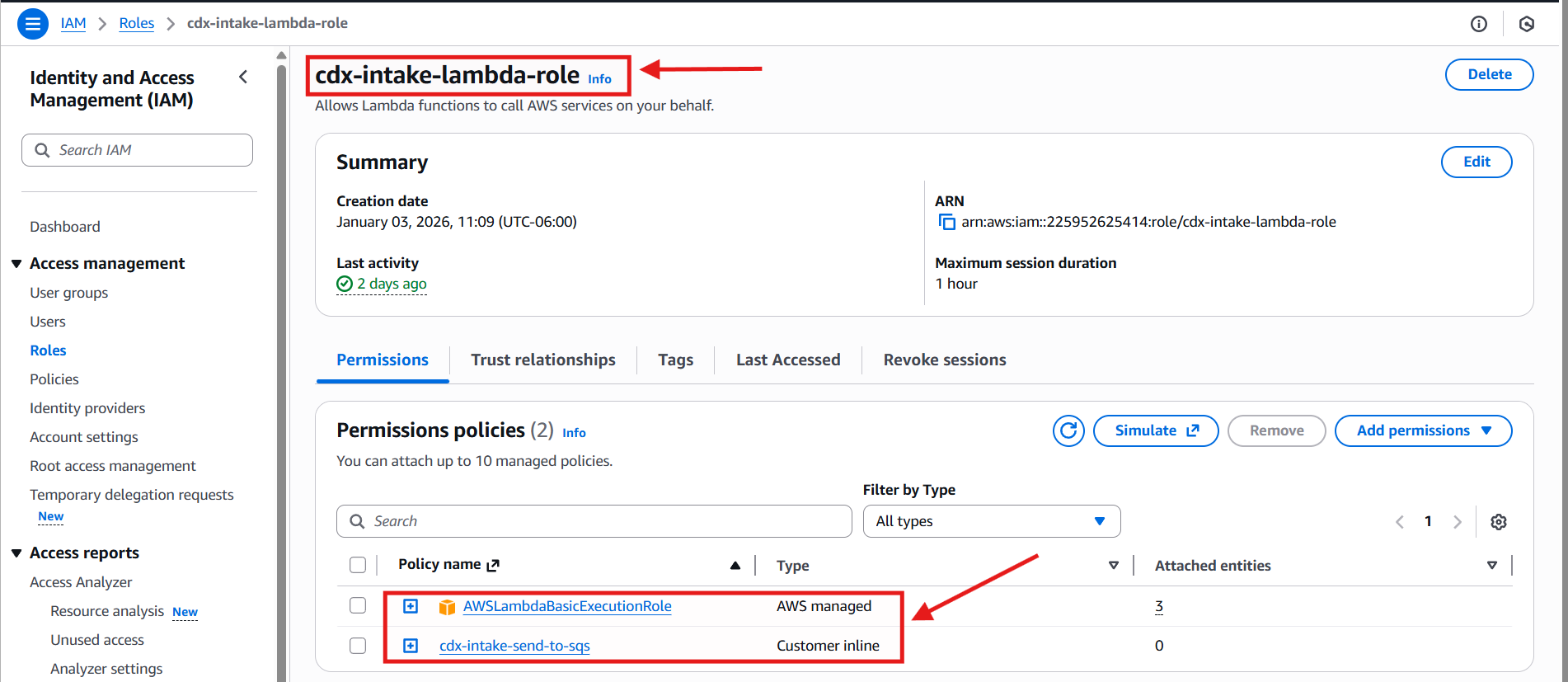
This least-privilege approach ensures the Lambda function can perform its task without broader access than necessary.
Create the Lambda Function (Python) with environment variables:
Next, I created the Lambda function responsible for parsing incoming scan payloads and enqueuing individual barcode messages.
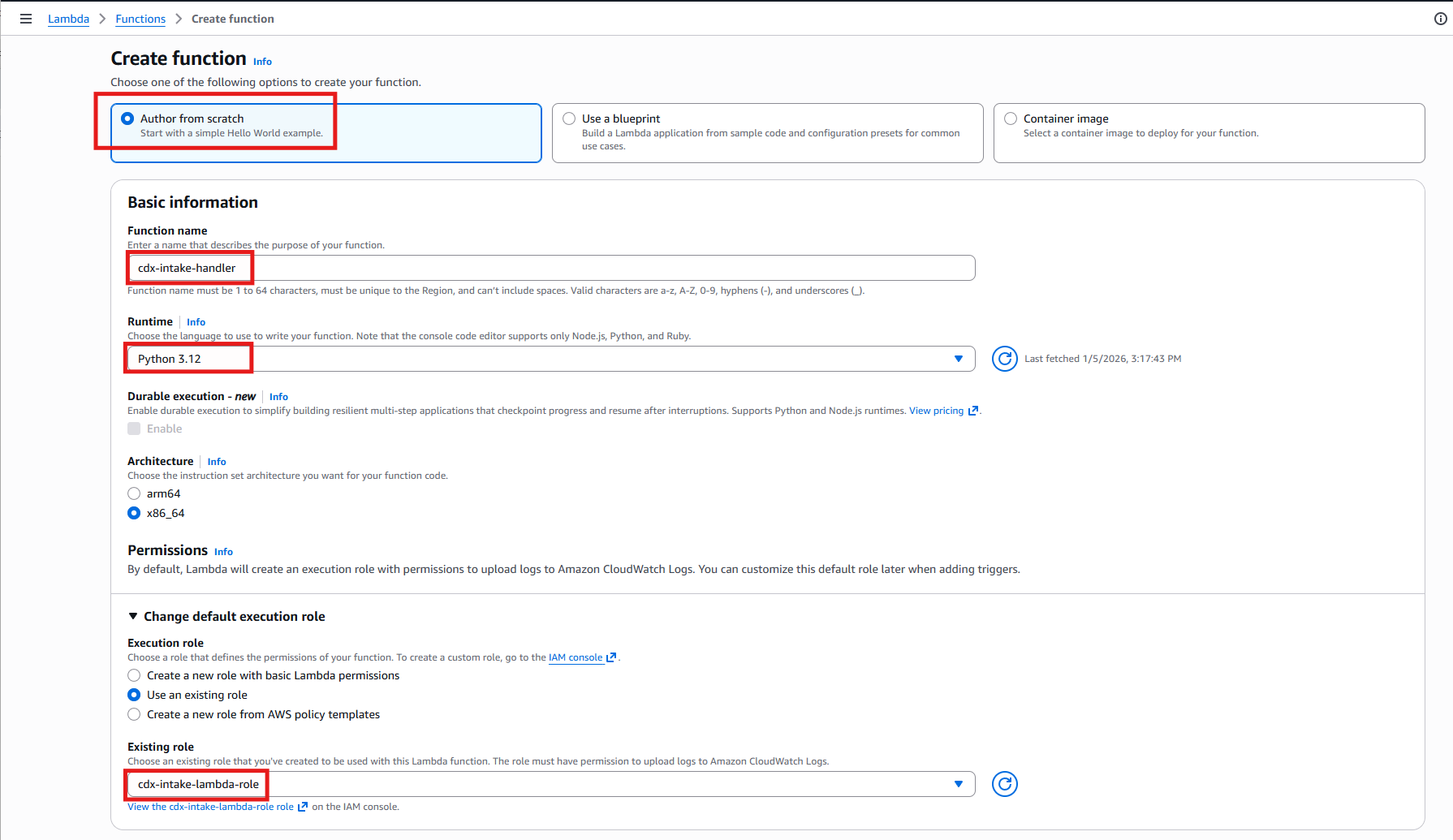
In the AWS Console, I navigated to Lambda → Create function, selected Author from scratch, and configured the function as follows:
- Function name:
cdx-intake-handler - Runtime: Python 3.12
- Execution role:
cdx-intake-lambda-role
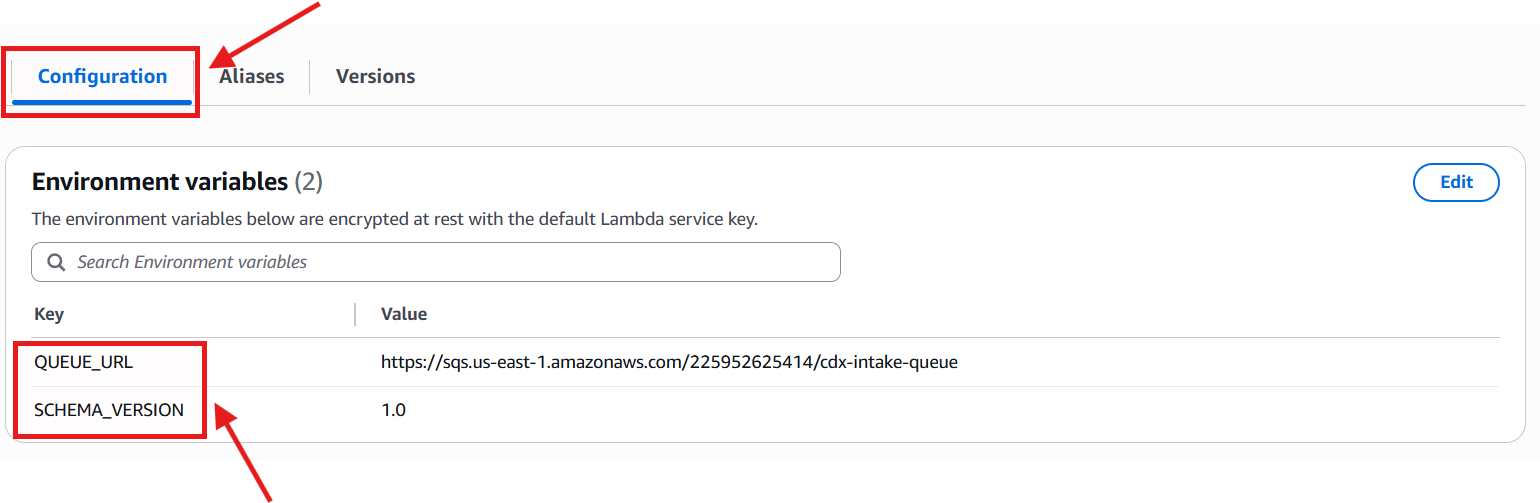
I also defined two environment variables:
- One to specify the target SQS intake queue
- One to track the current scan schema version, allowing future schema evolution without breaking downstream consumers
With assistance from AI (ChatGPT), I created and deployed a Python handler that:
- Receives a batch of barcode scans via API Gateway
- Parses the incoming JSON payload
- Builds a durable unit of work for each individual scan
- Enqueues each message into Amazon SQS for downstream enrichment
The message-building function constructs a well-structured, self-describing message for each scanned CD barcode:
def _build_message(payload: Dict[str, Any], item: Dict[str, Any]) -> Dict[str, Any]:
# One durable unit of work for the enrichment worker
return {
"schema_version": SCHEMA_VERSION,
"message_type": "cdx.enrich.request",
"request_id": str(uuid.uuid4()),
"ingested_at": _utcnow_iso(),
"source_system": payload.get("source", "cdx-web-scan"),
"submitted_at": payload.get("submitted_at"),
"scan": {
"captured_at": item.get("captured_at"),
"code": item.get("code"),
"format": item.get("format"), # "UPC" or "EAN" as provided
"source": item.get("source"), # "manual" / "camera" / "scanner"
"operator_title_desc": item.get("operator_title_desc"),
},
}Each message represents a single, immutable request that can be retried, replayed, or enriched independently, an important design principle for scalable, distributed pipelines.
Create API Gateway Route to the Lambda Function:
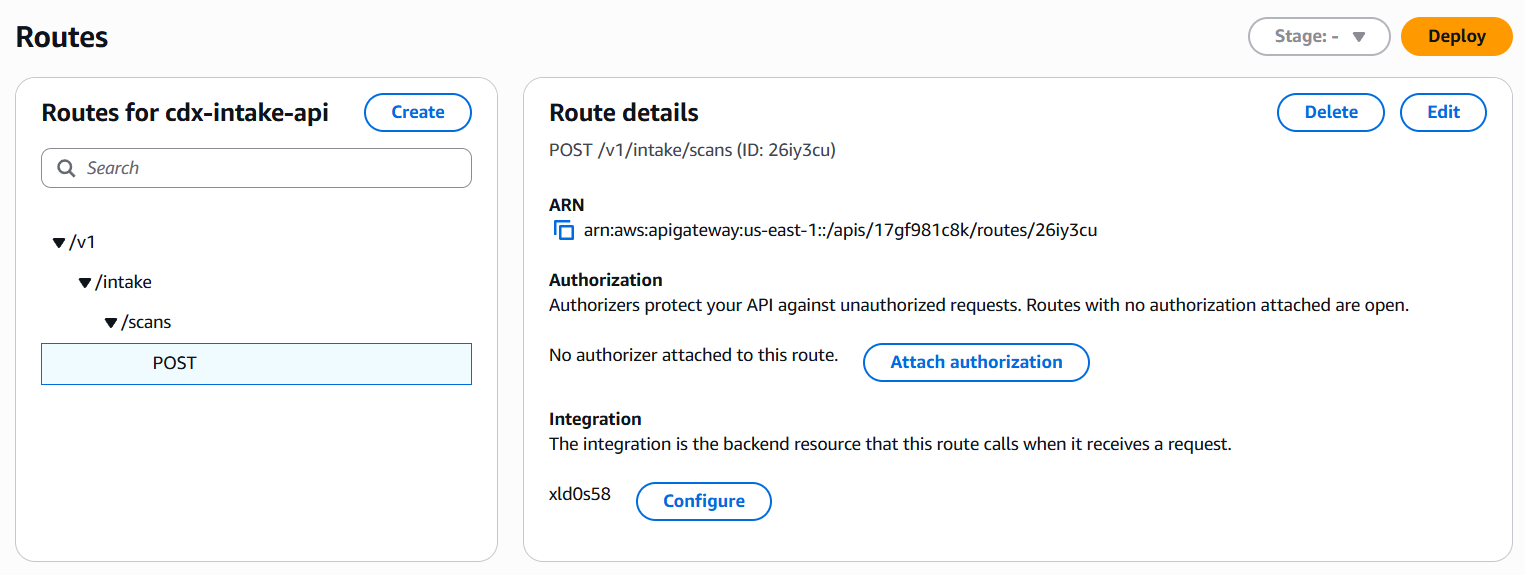
With the Lambda function in place, I exposed it to the CDX pipeline using Amazon API Gateway.
I created an HTTP API with an integration to the cdx-intake-handler Lambda function. The API exposes:
- Method:
POST - Path:
/v1/intake/scans
This endpoint serves as the public entry point for the CDX Web Scan application to submit batches of barcode scans into the cloud pipeline:
With the API Gateway, Lambda Function, and SQS Intake Queue in place, I was ready to test this section of the pipeline!
AWS Intake testing with Postman:
To validate the end-to-end intake flow, I used Postman (https://www.postman.com/), a popular API development and testing tool.
Using Postman, I simulated a request from the cdx-web-scan application by submitting a JSON payload containing a batch of scanned barcodes that conformed to the current schema:
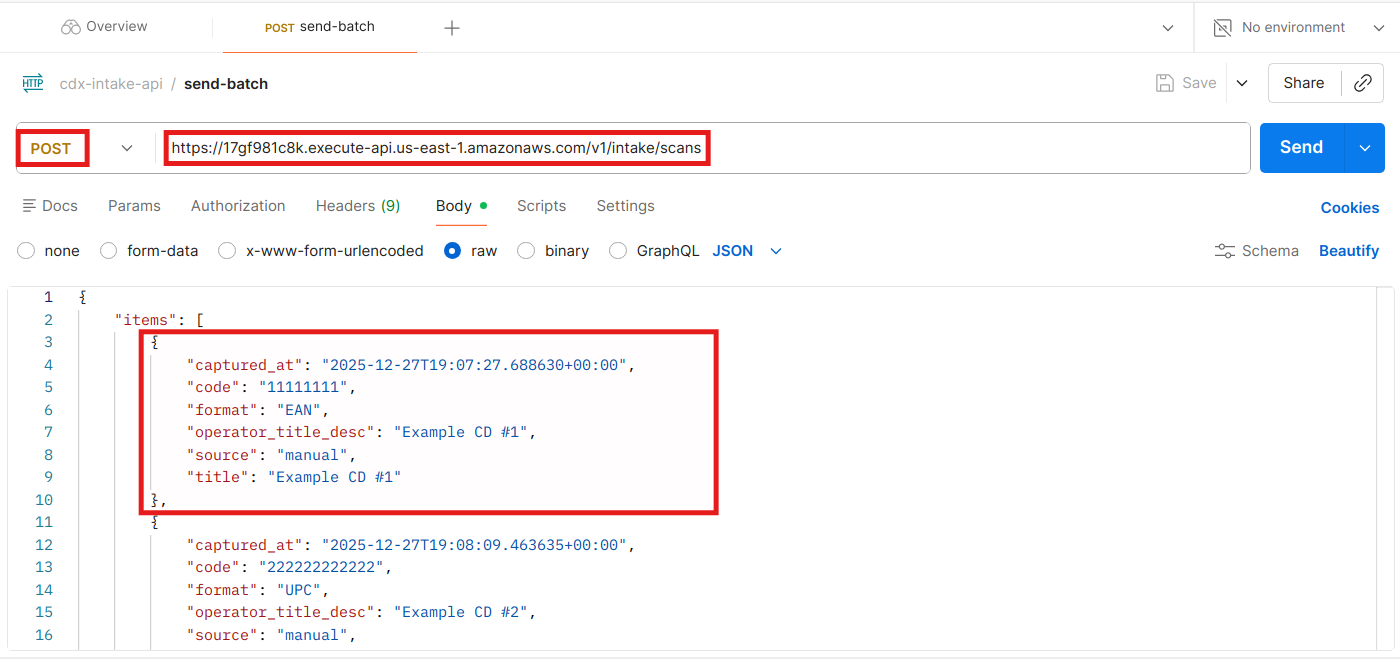
Submitting the POST request returned a successful HTTP 202 (Accepted) response, indicating that the request was received and queued for processing.
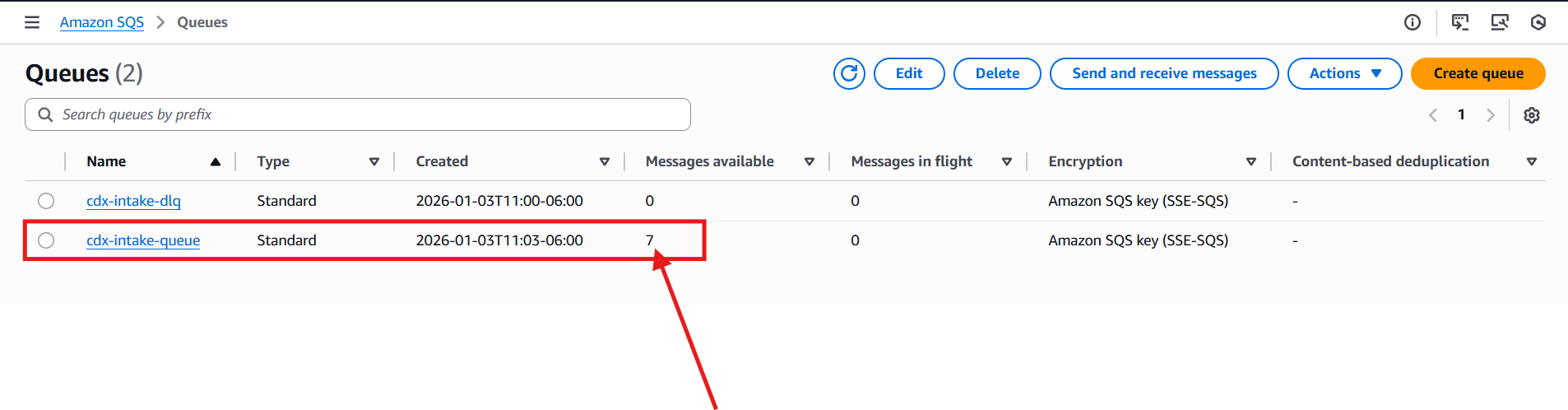
The Lambda function successfully parsed the batch and enqueued all 7 individual CD barcode scans:

When I returned to the AWS Web Console and navigated to Amazon SQS, I confirmed that 7 new messages had been added to the cdx-intake-queue:
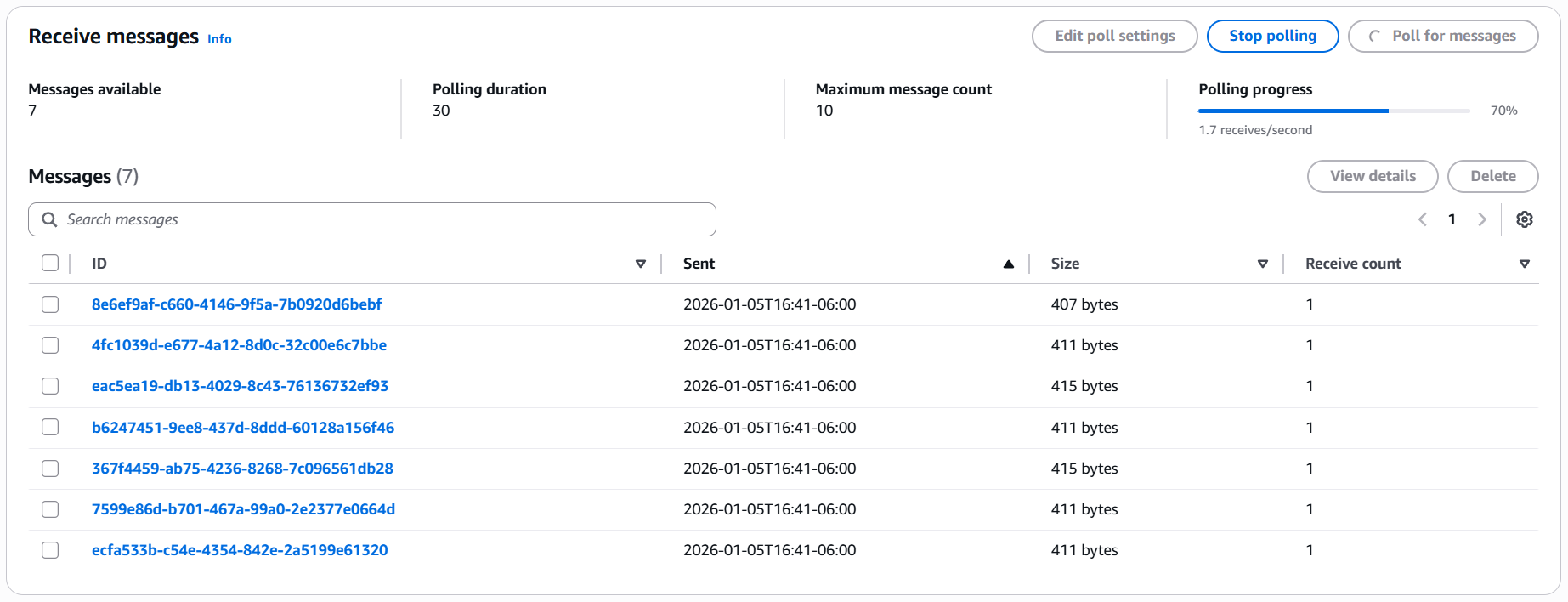
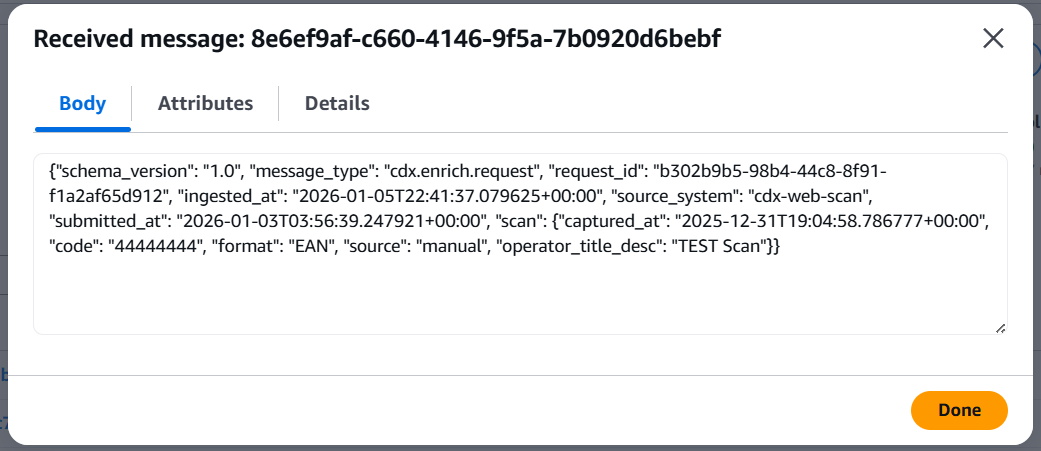
Inspecting the messages showed that each one contained the expected scan metadata and structure:
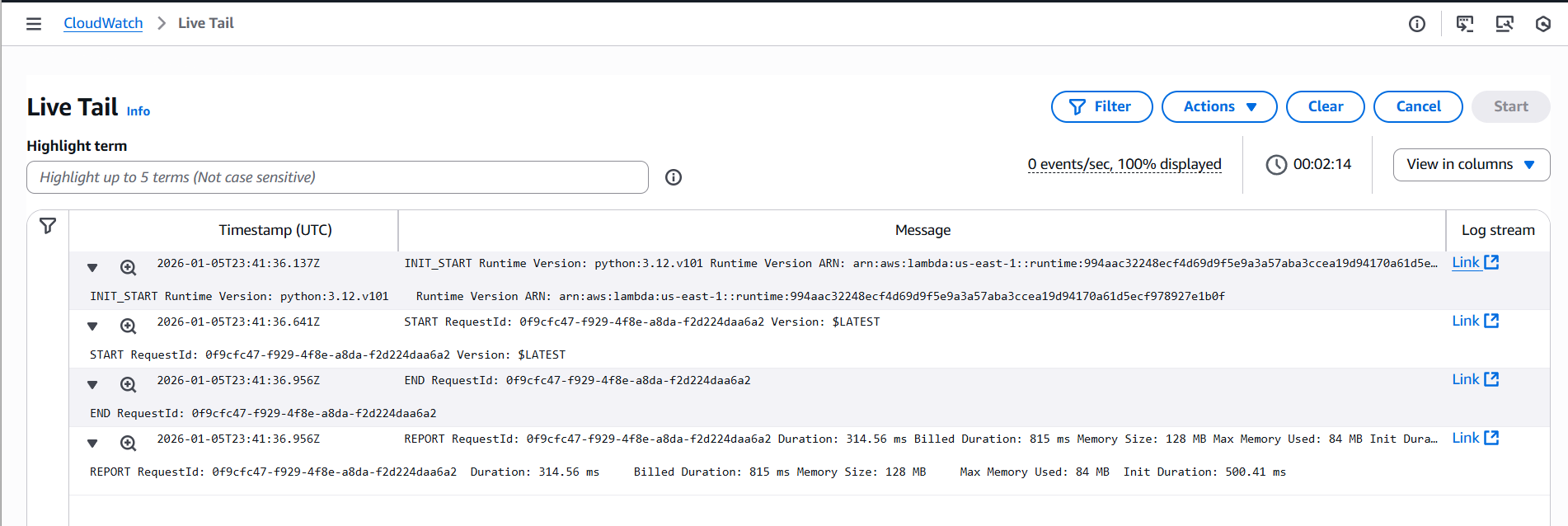
Lastly, I confirmed AWS CloudWatch was receiving the log from the Lambda function:
At this point, the cloud-based intake portion of the CDX pipeline was fully functional and ready to feed downstream discovery and enrichment services!
Wrap-up
In this post, I walked through the initial cloud-side implementation of the CDX intake pipeline, focusing on building a durable, serverless ingestion layer using core AWS services. By combining Amazon API Gateway, AWS Lambda, and Amazon SQS, I established a receiving mechanism for barcode scan data that cleanly decouples ingestion from downstream processing.
This design ensures that each scanned CD barcode is transformed into an independent, durable unit of work that can be safely queued, retried, inspected, or replayed as needed. The inclusion of a Dead-Letter Queue (DLQ) adds an additional layer of operational safety, allowing failures to be isolated without disrupting the primary intake flow.
From a cost and operational perspective, this architecture remains highly efficient: it is fully serverless, scales automatically with demand, and incurs little to no cost during idle periods, making it ideal for both hobby-scale projects and enterprise-style workflows. More importantly, it mirrors the same ingestion and queuing patterns commonly found in production-grade systems handling inventory, asset onboarding, and data enrichment pipelines.
In parallel with this cloud work, I’m in the process of deploying the cdx-web-scan application to a live, on-premises server. In the next post, I’ll focus on linking these two pipeline modules together, connecting the on-prem intake UI directly to the AWS-backed ingestion layer and validating the full end-to-end flow from physical barcode scan to durable cloud queue.
With the intake path now validated and the deployment groundwork underway, the CDX platform is ready to move into its next phase: building out the discovery and enrichment worker that consumes these messages and produces album and EP metadata, enabling me to truly explore, analyze, and rediscover insights within my fairly extensive CD collection.